Introduction
This is by no means a thorough analysis. It's merely a quick discussion and highlight of my findings while working on a new LummaC2 version. I managed to write a config extractor which can be found here : https://github.com/lowlevel01/config-extractors/blob/main/lumma.py
Sample hash : sha256:820a1d5a52a6afbf36fe4c00e4d65716d3f796b53eab4c2bcd93a193e95a376d
TLDR;
- A new Lumma version that uses fnv1a hashing algorithm instead of MurMur2 for Dynamic API Resolving
- Hashing algorithm not identified by the Hash-db plugin
- ChaCha20 encrypted config. In this case, the 4 nullbytes mentioned by eSentire's blogpost are not appended to the nonce which is kept 8 bytes long
The config extractor:

new API Hashing algorithm
This new version uses FNV1A hashing algorithm instead of MurMur2 for Dynamic API Resolving.

The prime number and the initial hash are decrypted from the stack at runtime.
Here is a re-implementation in python:
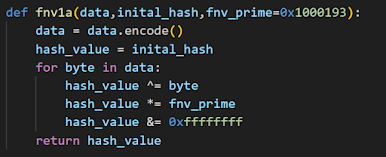
A friend of mine with good crypto knowledge, pointed out that we can extract the initial hash if we have a data and its corresponding hash. This can be easily seen since the xor is inversible and also the multiplication since the bianry AND is the same as modulo. The prime number and the modulo factor are co-prime therefore there exists an inverse.

I should note that this algorithm is not identified by OALabs's IDA Pro hash-db plugin. So, one needs to rebuild the API hash list from scratch. Write some emulation code to decrypt the prime number and initial hash and some IDAPython code replace every hash with its corresponding function.

How is the config stored
This version uses ChaCha20 to decrypt the C2 servers which is not news.
The ChaCha20 algorithm can be identified by the left rotations by 16, 12, 8, 7 in this order


I used a debugger to locate where the signature was first used (or precisely decrypted).

The signature was decrypted from the stack by an algorithm that takes each character, XORs it with a byte (0x3C in this case) and adds a byte to it(0x88 in this case) then use the result as the XOR key for the next byte and so on and so forth. The signature is then moved from its location to right before where the key is located.
But we only care about the key and the nonce.
Went back a little bit in the disassembly and noticed some global references being moved in the stack. Suspected it was the key and nonce. Lengths confirmed it as I was expecting a 32 byte key and an 8 byte nonce.
Reproducing the decryption on cyberchef to make sure we're good

The encrypted C2's, key and nonce are in the PE file with no extra treatment meaning you find a way to locate the key and nonce and dercrypt the C2's. I used a code signature to identify the beginning of the key (32 bytes), the nonce (8 bytes) is right after it and the C2's are right after the nonce.
Each C2 is in a block of 128 bytes.
I should note that, in this version, no null bytes are appended to the nonce as opposed to what was mentioned in eSentire's blogpost, so this is a new version.
Conclusion,
Again, this is by no means a full analysis. I just wanted to share these findings as they weren't mentioned online. This version same as the others uses control flow obfuscation heavily, Google published some research on this but it's theoretical. Who knows, maybe if I have time I'll tackle the control flow obfuscation part.
Comments
Post a Comment